



לשחרר את הדאטה: כיצד Data Lakehouse ו-Starburst משנים את כללי המשחק בניהול נתונים ובינה מלאכותית
מאמר משותף מאת עמיר אסולין, Sales Executive, Unstructured Data Solutions ב-Dell Technologies ויוסי רודריק, מייסד ומנכ"ל קבוצת UCL וחברת הבת Aqurate
מבוא: האתגר שבדאטה בעידן של האצה דיגיטלית
המהפכה הדיגיטלית של העשור האחרון טרפה את הקלפים – לא רק בעולם הטכנולוגיה, אלא גם במבנים הארגוניים, במודלים העסקיים ובאופן שבו מתקבלות החלטות. היום, נתונים אינם רק תוצאה של פעילות עסקית – הם הנכס האסטרטגי החשוב ביותר של כל ארגון. אך נכס זה מאופיין באתגרים לא פשוטים: מקורות מידע מפוזרים, כפילויות, זמינות נמוכה, קושי בשליפה ובשימוש. חסמים אלו מונעים בינה מלאכותית אפקטיבית.
במילים אחרות, הבעיה כבר אינה בהבטחה הטכנולוגית של AI, אלא בתשתית הנתונים שנדרשת לתמוך בה.
כנותני שירותים לארגונים במגוון תחומים, גדלים, זיקה לטכנולוגיה אנחנו נחשפים שוב ושוב לארגונים שמחזיקים במידע עשיר – אך לא מצליחים להפוך אותו לתובנות. מדוע? משום שארכיטקטורת הדאטה שלהם לא בנויה לעידן הנוכחי.
זו הסיבה שפתרון כמו Data Lakehouse לא רק הפך רלוונטי – אלא קריטי. זהו מודל שמאפשר לארגונים להפעיל את הנתונים מכל מקום, בכל זמן, ולכל שימוש – ללא צורך בשכפול, סרבול או ויתורים על אבטחה.
במאמר זה נצלול לעומק התפיסה הזו, נסקור את הרקע ההיסטורי והטכנולוגי שלה, נציג את החידושים שהשותפות בין Dell Technologies ו-Aqurate מביאה לשולחן, ונשתף בסיפור הצלחה מוכח של אחד הארגונים הגדולים בישראל: קבוצת מנורה מבטחים. זהו אינו חזון עתידי – אלא פרקטיקה שמתרחשת כבר היום.
מורה נבוכים: ההתפתחות ההיסטורית – מ-Big Data ל-Data Lakehouse
Big Data: פריצת הדרך הראשונה
בעשור הקודם, התעוררה ההבנה שארגונים מייצרים כמויות מידע עצומות – בקצב, בנפח ובמגוון חסרי תקדים. אתגר זה כונה Big Data, והתמקד בשלושה עקרונות (V3):
- Volume – נפח אדיר של נתונים.
- Velocity – מהירות יצירה וזרימה.
- Variety – סוגים שונים של מידע: טבלאי, טקסט, מולטימדיה, ועוד.
המערכות המסורתיות לא ידעו להתמודד עם השטף הזה. ארגונים החלו לאמץ כלים חדשים כגון Hadoop ו-NoSQL, אולם אלו דרשו יכולות טכניות כבדות והציגו חוויית ניתוח נתונים מורכבת.
Data Lake: שלב האגירה
כדי לפתור את בעיית הפיזור, הגיע השלב הבא – Data Lake: מאגר אחיד ורחב היקף שמאפשר להכניס אליו כל סוג של מידע, בכל פורמט, בכל זמן – גם בלי להגדיר סכמות מראש. החיסרון היה ברור: הנתונים נצברו, אך לא היו נגישים באמת לניתוח. אם להישאר בעולם במטאפורות לאגם, זה היה "אגם קפוא" – יפה למראה אך ללא שימוש.
Data Lakehouse: השלב המשחרר
כאן מגיעה הפריצה הגדולה. Data Lakehouse מאחד את היתרונות של Data Lake (אגירה חופשית, בקנה מידה עצום) עם המבניות והביצועים של Data Warehouse – אבל על בסיס תקנים פתוחים כמו Apache Iceberg או Delta Lake. הוא מאפשר גישה ישירה, בזמן אמת, לנתונים מכל הסוגים – ללא שכפול, וללא תלות בענן או כלי ספציפי.
זהו פתרון אידיאלי לארגונים שרוצים לפעול בעולם של AI, אנליטיקה מתקדמת ו-Real-Time BI, תוך שמירה על חופש בחירה תשתיתי וגמישות טכנולוגית.
Dell Technologies ו-PowerScale: תשתית הדאטה של הדור הבא
Dell Technologies מספקת את השכבה הפיזית הקריטית להפעלת Open Lakehouse בארגונים. בלב הפתרון עומד Dell PowerScale – מערכת אחסון מבוססת Scale-Out NAS, שתוכננה בדיוק לעומסי עבודה של דאטה מודרני.

היתרונות הבולטים של PowerScale:
- סקלאביליות אמיתית: התרחבות ללא הפרעה – מ-Terabytes לפטה-בייטים.
- תמיכה בפרוטוקול S3: התאמה מלאה ליישומי ענן ו-AI.
- Multi-Protocol: גישה אחידה גם ל-NFS, HDFS ו-REST.
- ביצועים: התאמה לעיבוד מקבילי, שאילתות כבדות ועומסי אנליטיקה.
- אבטחה ואמינות: הצפנה, זיהוי חדירה, בקרות גישה, תאימות רגולטורית.
מערכת זו מהווה את הבסיס עליו פועל מנוע Starburst – מריץ שאילתות על כל מקור נתונים, בלי להזיז את הנתונים עצמם.
Starburst: מנוע האנליטיקה שמאפשר גישה אחודה וחופשית
Starburst, המבוסס על Trino (לשעבר PrestoSQL), מאפשר לארגונים להריץ שאילתות SQL סטנדרטיות על מגוון מקורות מידע – בענן, מקומית, ב-Data Lake או ב-Warehouse – כאילו היו מקור אחד.
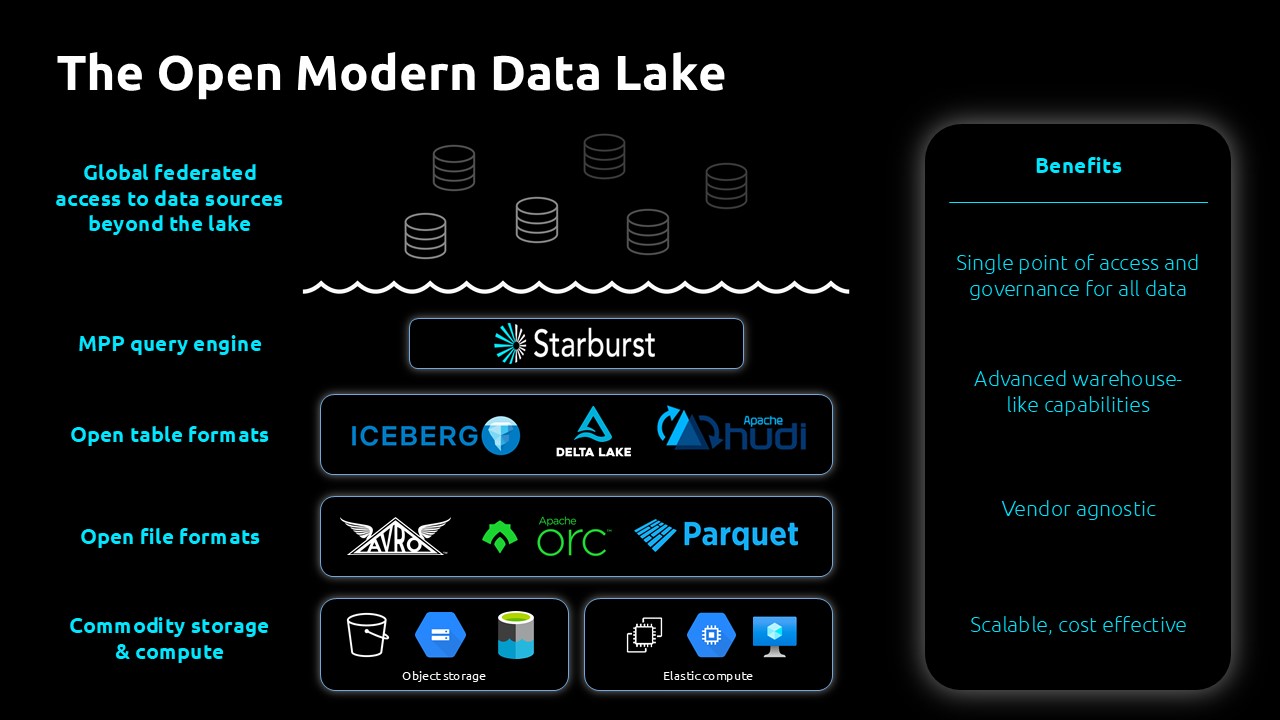
המשמעות היא פשוטה: ניתן להריץ אנליטיקות בזמן אמת, ללא צורך בשכפולים, תהליכי ETL מיותרים, ובאופן מאובטח.
מערכת ה- Starburst כוללת:
- Federated Query Engine
- אינטגרציה עם BI ו-Data Science
- Smart Caching, Indexing ו-Elastic Scaling
- Warp Speed המאפשר שיפור של פי 3-5 בזמני הרצת השאילתות
- אבטחה מקצה לקצה כולל Data Masking ו-Audit Logs
סיפור הצלחה: מנורה מבטחים – מהלכה למעשה
מנורה מבטחים התמודדה עם אתגר קלאסי: שילוב של מערכות תפעוליות מקומיות, דאטה היסטורי ונפחי מידע ענקיים.
באמצעות שילוב חכם של:
- Data Lake מבוסס Iceberg
- שכבת וירטואליזציה עם Starburst
- תשתית PowerScale + AWS + Snowflake
החברה הצליחה:
- להפחית את עומסי ה-ETL
- לספק נתונים בזמן אמת לצוותי פיתוח וביזנס
- לשפר ביצועי AI בתחום איתור ההונאות
- לקצר את זמני הפיתוח ואת ה-Time to Market
מגמות שוק ותחזית קדימה
על פי נתוני IDC כ- 83% מהנתונים בעולם עדיין יושבים on-prem. במקביל, 82% מהארגונים מתכננים להפעיל AI בסביבה מקומית. המשמעות: העתיד הוא היברידי – והפתרון חייב להתאים לכך.
פתרון Data Lakehouse הינו הפתרון היחידי המאפשר לארגונים להפעיל את הבינה המלאכותית במקום בו הנתונים נמצאים, מבלי לפגוע בביצועים, באבטחה או בעצמאות שלהם.
לסיכום
כדי להפעיל AI אמיתי – צריך לשחרר את הדאטה.
כדי לשחרר את הדאטה – צריך ארכיטקטורה פתוחה, היברידית, מאובטחת.
Dell Technologies ו-Aqurate מביאות פתרון מוכח – עם תשתית חומרה מובילה, ארכיטקטורת Data Lakehouse מתקדמת, ומנוע גישה אחוד לנתונים מכל מקור.
הזמן לפעול – הוא עכשיו.